Peripateticism
Yuens' blog

基于头部姿态角变换的活体检测
我做了两种活体检测:配合式、非配合式。
- 配合式:一般用于证券/电话卡等账户开户,用户根据指定动作(眨眼、左右转头、左右摇头、点头)判断活体。如睁眼闭眼(一种做法是对检测得到的人脸的眼睛关键点,抠出眼睛部分,对睁眼闭眼进行分类);
- 非配合式:用于安防、门禁等场景。就说基于双目摄像头(可见光、红外)的实现原理:可见光和红外摄像头分别采集到三通道彩图和单通道图,将三通道图用于人脸检测,将检测得到的人脸坐标放置在单通道图像上,观察是否有人脸,若有则为活体转而进入后续的任务,如识别,否则就不是活体,可能是一张照片。
一般而言,配合式的活体检测精度更高,两种方式各自都有多种实现方式。下面以配合式活体检测的其中一种方法展开讲解。
注:下面关于优化方法的部分(牛顿法、拟牛顿法、高斯牛顿法)未完待续,具体见issue,打算新开一篇
1. 什么是物体姿态和PNP问题
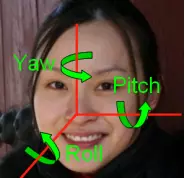
在计算机视觉中,物体的姿势指的是其相对于相机的相对取向和位置,一般用旋转矩阵、旋转向量、四元数或欧拉角表示(这四个量也可以互相转换)。一般而言,欧拉角可读性更好一些,也可以可视化(见下图,分别对应欧拉角的三个角度),所以常用欧拉角表示。欧拉角包含3个角度:pitch、yaw、roll,这三个角度也称为姿态角。
姿态角/欧拉角动图注解
pitch():俯仰,将物体绕X轴旋转(localRotationX)
yaw():航向,将物体绕Y轴旋转(localRotationY)
roll():横滚,将物体绕Z轴旋转(localRotationZ)

确定物体的姿态就是要计算其相对相机的欧拉角,刚提到也可以是旋转矩阵。旋转矩阵可以和欧拉角相互转换,一般而言,得到的欧拉角可以可视化到二维图像上,见下图。
姿势估计问题通常称为Perspective-n-Point问题或计算机视觉术语中的PNP。在该问题中,目标是在我们有校准相机时找到物体的姿势或运动(即找到欧拉角或旋转矩阵),还需要知道物体上的n个3D点的位置以及相应的相机3D到图像2D平面的投影。即,我们需要三个东西(后文会说到为什么需要这三样):
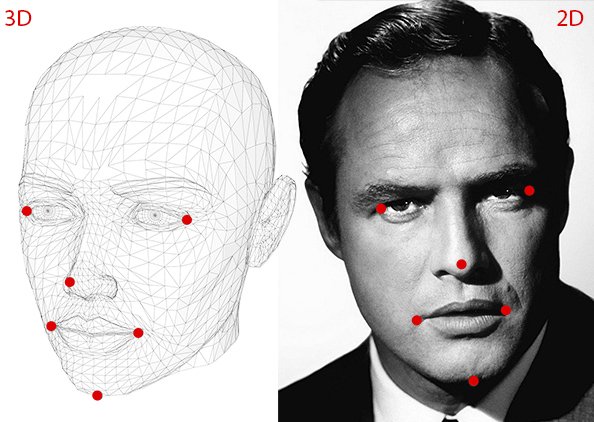
- 物体(人脸)在相机3D世界中投影到二维平面的坐标。即图像上人脸的关键点,比方我们这里是五个关键点或者六个,那么就要给出这几个点在二维平面上的坐标。因为我们已有模型计算得到的人脸关键点信息(这个也可以用Dlib/OpenCV得到,Dlib提供计算人脸68个关键点的模型与接口),所以这个是已知的。
- 物体与2D平面相对应的3D世界坐标系位置。可能你会认为需要照片中人物的3D模型才能获得3D位置。理想情况下是的,但在实践中我们一是没有,二是通用3D模型就足够了。获得完整头部的3D模型,只需要知道在某个任意参考系中的几个点的3D位置。下面我们以鼻子为3D世界坐标系的原点位置(0,0,0)。得到以下人脸3D点(以下几个点是任意参考系/坐标系中,你还可以根据自己情况修改校准,这称为世界坐标,也即OpenCV docs中的模型坐标):
- 鼻尖:(0.0,0.0,0.0)
- 下巴:(0.0,-330.0,-65.0)
- 左眼左角:( - 225.0f,170.0f,-135.0)
- 右眼右角:(225.0,170.0,-135.0)
- 口的左角:( - 150.0,-150.0,-125.0)
- 嘴角:(150.0,-150.0,-125.0)
- 物体在3D世界中对应相机中3D坐标系的位置,知道了3D世界中的坐标点通过相机参数可以算出,换句话说,这一步是要知道相机参数(相机焦距、图像中的光学中心、径向失真参数)。因为这不是软件层面的事情,所以我们这里假设相机被校准,使用校准相机的参数。我们通过图像的中心来近似光学中心,以像素的宽度近似焦距,并假设不存在径向畸变。
2. 如何在数学上表示物体相对相机的运动?
在此前,我们先看看怎么表示物体在3D世界坐标中的运动(即如何让3D世界坐标下的物体运动到相机3D世界中去)。3D刚性物体相对于相机的运动,仅具有两种运动:
- 平移(Translation):将相机从当前3D位置
(X,Y,Z)移动到新的3D位置(X',Y',Z')称为平移,平移具有3个自由度,即可以沿X,Y或Z方向移动。平移由向量t表示(X' - X,Y' - Y,Z' - Z)。 - 旋转(Rotation):可以旋转摄像头的X、Y和Z轴,即旋转也具有三个自由度。有许多表示旋转的方法,常见的如欧拉角(包含滚动角,俯仰角和偏航角,对应roll、pitch、和yaw),即一个
3x3维度的旋转矩阵或者3x1维度的旋转向量,或者用一个旋转方向(即轴)和角度来定义。
因此,估计3D对象中某一个点的运动,意味着找到该点的平移与旋转的6个参数 (这里,假定旋转用1x3维度的旋转向量表示):3个用于平移,3个用于旋转。那么我们就描述完了如何将3D世界中的坐标点转换到3D相机世界中去,这是第一个转换。
但需要注意的是,我们需要知道物体3D世界中的点,而且一个假定是面部特征的3d坐标是基于世界坐标。这部分内容就是将物体在3D世界中的点,平移旋转到3D相机世界坐标的方法,但我只知道相机参数,并不知道物体在3D相机世界中的坐标。
3. 姿势估计算法如何工作?
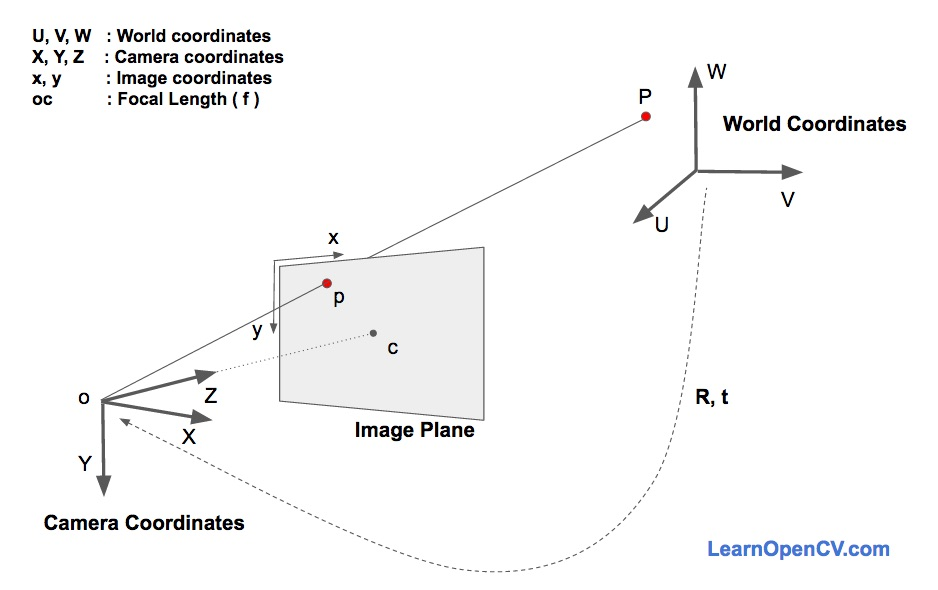
别急,你看上图里有三个坐标系(世界3D坐标World Coordinates、相机3D坐标Camera Coordinates、投影平面坐标即图像Image Plane)。前文中有一张图片显示就是面部特征在世界3D坐标中的样子,以及对应2D图像Image Plane上的样子。如果我们知道,从人脸在世界3D坐标中的位置,到人脸在相机3D世界的位置的旋转和平移(即姿势/物体运动)参数,那么就可知道人脸在相机3D坐标中的位置。
仍旧看上图,可以发现相机3D坐标Camera Coordinates与投影平面坐标即图像Image Plane,二者的X和Y是一样的。现在我们知道世界坐标中位置P的3D点为(U,V,W)。如果知道相对于相机坐标的世界坐标的旋转矩阵R(3×3矩阵)和平移b(3×1矢量),就可以使用以下等式计算相机坐标系(X,Y,Z)中点的位置P。
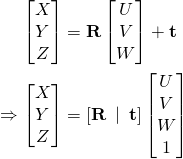
也可以写成扩展的形式:

如果我们知道足够数量的点对,即(X,Y,Z)和与之对应的(U,V,W),上面就是一个线性方程组,可以求解得到旋转R和平移b的值。但该方法也有缺点(具体见下文方法2),正如前面所说,描述物体运动需要旋转和平移,对应3个方向6个值,这个方法一个3D点的平移参数算出是3个值,但是旋转参数却有9个(假定我们这里不考虑使用3x3维度的旋转矩阵,而是想要使用3x1维度的旋转向量)。
3.1 方法1:直接线性变换(DLT)求解参数
在上面的方程中,我们有很多已知的3D世界坐标点,即(U,V,W),但不知道具体的3D相机坐标(X,Y,Z),但知道3D相机坐标中的X和Y,即2D图像上的关键点。在没有径向畸变(即z点的畸变)的情况下,2D图像坐标中P点即(x,y)有以下公式:
PS:下面公式描述了,将相机坐标(X,Y,Z)转换即投影为平面坐标(x,y,1)的过程,已知平面坐标和相机参数,通过下面公式算出相机坐标(X,Y,Z):
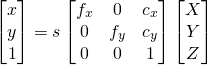
其中,f_x和f_y是在x和y方向上的焦距,并且(c_x,c_y)是光学中心。当涉及径向变形时,事情变得稍微复杂一些,为了简单起见不考虑这一项。
s是一个我们未知的比例因子,表示深度信息。举个例子,若将3D世界坐标中某个点P与3D相机坐标中对应的点P连接起来,即光线,那么这个光线会与图像平面相交得到二维平面上的点P。这个s就是这个过程中变换的深度信息,但我们这里因为未知,统统将所有点s考虑为一样的。
PS:以下公式,将3D世界坐标(U,V,W)转换为3D相机坐标,已知3D世界坐标和上面公式算出的3D相机坐标,因而可以算出3x3的旋转矩阵和3x1的平移向量。

基于上面的两个公式,先用第一个公式计算出Z值,再用第二个公式计算出旋转矩阵,依次列出方程组,依次求解得到3D相机坐标的值Z、旋转R和平移T参数。这种方法称为直接线性变换(Direct Linear Transform,DLT)。然后再讲旋转矩阵转换为欧拉角。
下面是补充内容,将3x3维度的旋转矩阵转换为欧拉角。
旋转矩阵转换为欧拉角
我们可以将旋转矩阵转换为欧拉角,从而得到姿态。已知维度为
3x3的旋转矩阵:基于旋转矩阵计算欧拉角的公式为:


这里
atan2就是arc tangent函数,调用该函数时会做象限的检查。该函数可在C或Matlab代码中找到。. 注:如果角度绕y轴是+ / -90°。在这种情况下,除了一个在角落较低的元素(不是1就是-1),其它所有元素都在在第一列和最后一行上都是0(因为cos(1)=0)。针对该问题,需要修正,即绕x轴旋转180°,并计算绕z轴的角度,可以用这个函数解决:atan2(r_12, -r_22)。 更具体参考:http://www.soi.city.ac.uk/~sbbh653/publications/euler.pdf。
- c++ - How to calculate the angle from rotation matrix - Stack Overflow
- 三维空间中的旋转:旋转矩阵、欧拉角 – Miskcoo’s Space
3.2 方法2:Levenberg-Marquardt
实际中,方法1的直接线性变换(Direct Linear Transform,DLT)计算结果不准确,因为:
- 旋转R有3个自由度需要的只是3个数字,但DLT方法使用的矩阵有9个数字,且DLT方法中没有任何方法使
3x3矩阵的意义是旋转矩阵(这里我有点懵,可能是说,3x3维度的这个矩阵其实际意义很难说带有旋转的意思在里面,因为没有最小化目标函数,这个算出的3x3的矩阵与旋转的参数意义不明确); - 直接线性变换(DLT)方法不会最小化正确的目标函数,我们希望最小化下面描述中的投影误差。
前文中的公式中,我们已经知道,若得到了正确的姿态R和t参数,就可以基于3D点信息以3D点投射到2D图像上的方式,来得到2D点信息。换句话说,知道了姿态参数R和t就可以知道每个3D点投影的2D点。
实际计算姿态前,我们已知2D点位置信息(比方用Dlib或手动选择点击得到关键点),假设也已知旋转R和平移t参数,那么基于2D点、R和t,我们可以算出2D点对应投影出的3D点(这个3D点是我们用参数R和t估算的),因为我们也知道真实的3D点,进而可以得到估算的3D点与真实的3D点二者的投影误差(re-projection error),即所有相对应点的距离平方和。
用前文中提到的两个公式(如上,再次列出),直接线性变换(DLT,direct linear transform)就是对姿态参数R和t的估计,想要改进一个最简单的方法就是修正R和t参数,看重投影误差有没有降低。如果降低,则接受新的R和t参数。但这个方法没有修正目标(每次加一点轻微扰动),而且很慢,一种名为LM的优化方法(Levenberg-Marquardt optimization),可以很好地解决这个问题,具体参考维基百科。
OpenCV的APIsolvePnP(PnP,Perspective-n-Point,即从3D点找到其对应的2D点),可以使用基于LM方法(Levenberg-Marquardt)进行姿态估计,只需要定义flag参数为CV_ITERATIVE即可(当然还有其他方法,见后文API说明),无论哪种方法的使用,都需要定义这三个参数:
- 3D坐标中的点
objectPoints; - 与3D点对应的2D坐标点
imagePoints。如人脸关键点位置信息(五点如左右眼睛、嘴唇左右、鼻子); - 摄像机的畸变参数
distCoeffs(一般是固定的,其中定义了焦距,光学中心等)。确保或者以该参数校准相机,不会有误差、错误的结果等。
有了上面三个参数交给LM优化算法,它就会使用相机的固有参数,结合世界坐标中的3D点与图像平面上的点信息,估计姿态的旋转R和平移t参数(即图像坐标系),反复迭代计算并寻找重投影误差最小时的旋转和平移参数,即我们最后期望的结果。
实际上,OpenCV有两个用来解决计算物体姿态函数接口:solvePnP、solvePnPRansac,第二个solvePnPRansac利用随机抽样一致算法(Random sample consensus,RANSAC)的思想,虽然计算出的姿态更加精确,但速度慢、没法实现实时系统,所以我们这里只关注第一个solvePnP函数,OpenCV提供其C++与Python接口,具体说明如下:
solvePnP
Finds an object pose from 3D-2D point correspondences.
- C++: bool solvePnP(InputArray objectPoints, InputArray imagePoints, InputArray cameraMatrix, InputArray distCoeffs, OutputArray rvec, OutputArray tvec, bool useExtrinsicGuess=false, int flags=ITERATIVE )
- Python: cv2.solvePnP(objectPoints, imagePoints, cameraMatrix, distCoeffs[, rvec[, tvec[, useExtrinsicGuess[, flags]]]]) → retval, rvec, tvec
Parameters:
- objectPoints – Array of object points in the object coordinate space, 3xN/Nx3 1-channel or 1xN/Nx1 3-channel, where N is the number of points. vector
can be also passed here. - imagePoints – Array of corresponding image points, 2xN/Nx2 1-channel or 1xN/Nx1 2-channel, where N is the number of points.vector
can be also passed here. - cameraMatrix – Input camera matrix .
- distCoeffs – Input vector of distortion coefficients of 4, 5, or 8 elements. If the vector is NULL/empty, the zero distortion coefficients are assumed.
- rvec – Output rotation vector (see Rodrigues() ) that, together with tvec , brings points from the model coordinate system to the camera coordinate system.
- tvec – Output translation vector.useExtrinsicGuess – If true (1), the function uses the provided rvec and tvec values as initial approximations of the rotation and translation vectors, respectively, and further optimizes them.
- flags –Method for solving a PnP problem:
- CV_ITERATIVE Iterative method is based on Levenberg-Marquardt optimization. In this case the function finds such a pose that minimizes reprojection error, that is the sum of squared distances between the observed projections imagePoints and the projected (using projectPoints() ) objectPoints .
- CV_P3P Method is based on the paper of X.S. Gao, X.-R. Hou, J. Tang, H.-F. Chang “Complete Solution Classification for the Perspective-Three-Point Problem”. In this case the function requires exactly four object and image points.
- CV_EPNP Method has been introduced by F.Moreno-Noguer, V.Lepetit and P.Fua in the paper “EPnP: Efficient Perspective-n-Point Camera Pose Estimation”. The function estimates the object pose given a set of object points, their corresponding image projections, as well as the camera matrix and the distortion coefficients. Note: An example of how to use solvePNP for planar augmented reality can be found at opencv_source_code/samples/python2/plane_ar.py
- pitch yaw roll 的区别 - 夜光猪 - 博客园
- 训练数据常用算法之Levenberg–Marquardt(LM) - 沉心修炼 - CSDN博客
- Camera Calibration and 3D Reconstruction — OpenCV 2.4.13.7 documentation
- 随机抽样一致算法(Random sample consensus,RANSAC) - 桂。 - 博客园
-
[Head Pose Estimation using OpenCV and Dlib Learn OpenCV](https://www.learnopencv.com/head-pose-estimation-using-opencv-and-dlib/) - 基于Dlib和OpenCV的人脸姿态估计(HeadPoseEstimation) - 二极管具有单向导电性 - CSDN博客
- 游戏动画中欧拉角与万向锁的理解 - huazai434的专栏 - CSDN博客
- Gimbal Lock(欧拉旋转的万向节锁)_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
4. Levenberg-Marquardt优化算法
【】 【】【】【】【】【】【】【】【】【】【】【】【】【】
- Levenberg-Marquardt算法浅谈 - liu14lang的博客 - CSDN博客
- 【LM算法论文】METHODS FOR NON-LINEAR LEAST SQUARES PROBLEMS
5. 旋转参数转换为欧拉角
副标题:旋转向量(角轴)、四元数与欧拉角的转换
前面我们使用OpenCV的solvePnP接口,得到了旋转向量R和平移向量t。现在我们需要将旋转向量R转换为欧拉角。后面有与之对应实现的具体代码。这个代码的过程包含以下两个转换部分:
- 旋转向量
rotation_vector——> 四元数(quaterniond,即w,x,y,z); - 四元数(quaterniond,即
w,x,y,z)——>对应的欧拉角(pitch、yaw、roll)。
注:更多旋转方面的转换公式见后面参考链接。
5.1 旋转向量(角轴)转为四元数
假设某个旋转是绕单位向量 n = [n_x, n_y, n_z]^T进行角度为\theta的旋转,则有四元数q:
q = [cos(\theta / 2), n_x sin(\theta / 2), n_y sin(\theta / 2), n_z sin(\theta / 2)] ^ T,- 即
q = [w, x, y, z]^T, - 其中有
|q|^2 = w^2 + x^2 + y^2 + z^2 = 1
该转换公式中的\theta加上2pi,得到一个相同的旋转,其对应的四元数变成了-q,即任意的旋转都可以由两个互为相反数的四元数表示。
对应如下代码:
# calculate quaterniond from rotation vector
theta = cv2.norm(rotation_vector)
w = np.cos(theta / 2)
x = np.sin(theta / 2) * rotation_vector[0] / theta
y = np.sin(theta / 2) * rotation_vector[1] / theta
z = np.sin(theta / 2) * rotation_vector[2] / theta
5.2 四元数转为欧拉角
得到四元数后,再计算欧拉角,公式如下:
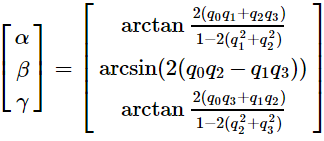
由于arctan和arcsin的取值范围在[−π/2, π/2],之间只有180°,而绕某个轴旋转时范围是360°,因此要使用atan2函数代替arctan函数:
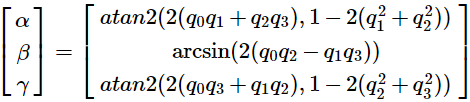
从四元数[w, x, y, z]转换为欧拉角的代码实现:
# quaterniond to eulerAngle
ysqr = y * y
xsqr = x * x
zsqr = z * z
# pitch (x-axis rotation)
t0 = 2.0 * (w * x + y * z)
t1 = 1.0 - 2.0 * (xsqr + ysqr)
pitch = math.atan2(t0, t1)
pitch = pitch * 180 / math.pi
# yaw (y-axis rotation)
t2 = 2.0 * (w * y - z * x)
t2 = 1.0 if t2 > 1.0 else t2
t2 = -1.0 if t2 < -1.0 else t2
yaw = math.asin(t2)
yaw = yaw * 180 / math.pi
# roll (z-axis rotation)
t3 = 2.0 * (w * z + x * y)
t4 = 1.0 - 2.0 * (ysqr + zsqr)
roll = math.atan2(t3, t4)
roll = roll * 180 / math.pi
if roll > 90:
roll = (roll - 180) % 180
if roll < -90:
roll = (roll + 180) % 180
计算得到的欧拉角是弧度,需要将弧度转换为角度,才是我们姿态估计时候的欧拉角,转换公式如下:
- 角度转弧度:π/180×角度
- 弧度变角度:180/π×弧度
- 弧度与角度的转化公式_作业帮
- 四元数与欧拉角(RPY角)的相互转换 - 冬木远景 - 博客园
- 半闲居士视觉SLAM十四讲笔记(3)三维空间刚体运动 - part 3 旋转向量、欧拉角、四元数 - youngpan1101的博客 - CSDN博客
6. 欧拉角与头部姿态
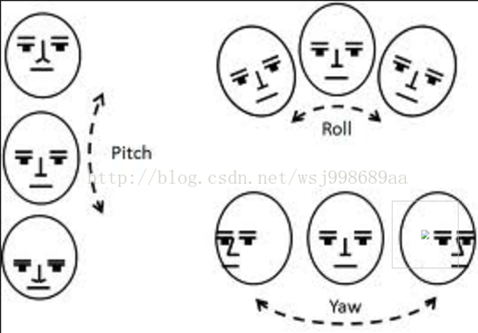
知道了欧拉角后,要确定头部姿态需要计算不同姿态对应的三个角度(pitch、yaw、roll)的值范围。常用的头部姿态有如下五个:左右摇头(水平45°倾斜,或者说是绕x轴旋转),左右转头(yaw,绕z轴旋转),抬头点头(一般看点头,不看抬头因为抬头和人脸正面差不多)。
这个参数需要调并校准,我在网上找了很多人脸图,然后对其旋转,得到3组图片:
- 从左到右水平转头的一系列图片;
- 从左到右摇头的一系列图片;
- 从上到下(抬头到点头)的一系列图片。
分别先跑网络得到关键点,观察计算出的角度,确认每张图片的角度范围。得出:
- 从左到右水平转头的一系列图片的欧拉角,即yaw,pitch,roll的角度变化范围;
- 从左到右摇头的一系列图片的欧拉角,即yaw,pitch,roll的角度变化范围;
- 从上到下(抬头到点头)的一系列图片的欧拉角,即yaw,pitch,roll的角度变化范围。
这个对应姿态的三个角度参数需要自己调整,从而判断当前的头部属于哪种姿态。
def get_pose(self, angle_dict):
pose_dict = {'down':0,'front':0,\
'turn_left':0, 'turn_right':0,\
'shake_left':0, 'shake_right':0}
# pitch
if -180<angle_dict['pitch'] and angle_dict['pitch']<-100:
pass #sose_dict['down'] = 1
elif 100<angle_dict['pitch'] and angle_dict['pitch']<180:
pose_dict['up'] = 1
# yaw
if -70<angle_dict['yaw'] and angle_dict['yaw']<-15:
pose_dict['turn_left'] = 1
elif 15<angle_dict['yaw'] and angle_dict['yaw']<70:
pose_dict['turn_right'] = 1
# roll
if 10<angle_dict['roll']<70:
pose_dict['shake_left'] = 1
elif -70<angle_dict['roll']<-10:
pose_dict["shake_right"] = 1
# front
if self.is_front(angle_dict):
pose_dict["front"] = 1
return pose_dict
def is_front(self, angle_dict):
if abs(angle_dict['yaw'])<10 and\
abs(angle_dict['roll'])<10 and\
abs(angle_dict['pitch'])>160:
return True
return False